writing a realtime translation app
Sometimes, the things we consume in our own language or languages just isn't enough. In a world where the popular show of the week might be a K-drama or your friend sends you the top Latin American hits but you might not understand a single world; there's only one way you can understand the media in front of you:
Transcription
Whether it's looking up Genius for music, or reading the subtitles on Netflix for a drama; a user's enjoyment is fully dependent on there being a transcription capable of communicating the content of whatever the particular media may be.
However, this means that each software or service must provide the transcription--for anyone who likes to consume lots of foreign media it becomes difficult to manage all the resources you might need.
Perhaps you've downloaded the movies and now need to find subtitles. There are many different lyric websites for different songs. Maybe there's a song that hasn't gotten a transcription yet.
In all of these cases, there is a dependency on some auxiliary service.
So, I set out to make an application that lets the user transcribe and translate anything that they might be listening to.
The setup
To design a product that could process any incoming audio, we need:
- Functionality agnostic of the media source, i.e, process audio not just Spotify data or YouTube data
- The ability to transform audio data into transcribed text
- Support for persistent and continous data processing
- Simple and straightforward ease of use to start and end audio processing at the user's whim
Thus, I chose the following:
- PyAudio with WASAPI, a patched PyAudio fork that allows recording from output devices in loopback mode. In other words, we can capture the audio from the user's default speakers.
- Whisper-tiny implemented with huggingface in pipeline form. The pipeline abstraction makes it simple to process audio as it is received
- To facilitate realtime transcription display, I designed a Websocket endpoint that persists as long as the user is transcribing incoming audio
- A very basic NextJS UI using shadcn/ui components.
Lastly, I wanted this application to be standalone--so I decided to choose Tauri, a relatively niche but growing framework for building binaries, as opposed to Electron and other common approaches. The idea of being based in Rust seemed like it might be a good fit for a realtime application, whilst also being something I'd never got the chance to work in.
Sidecars | Communicating between Python and Tauri
It isn't and wasn't immediately straightforward to determine how I might utilize huggingface relative to Tauri. My expertise is in PyTorch and the Python ecosystem--so if I was designing a Websocket API I'd most likely end up doing it in FastAPI.
Fortunately, Tauri supports embedding external binaries--also known as a sidecar.
Once the sidecar is added to the Tauri config, we can write some code in main.rs to execute the sidecar on app startup:
fn start_backend(receiver: Receiver<i32>){
let t = TCommand::new_sidecar("main").expect("[Error] Failed to create 'main.exe' binary command");
let mut group = Command::from(t).group_spawn().expect("[Error] spawning api server process.");
thread::spawn(move || {
loop{
let s = receiver.recv();
if s.unwrap() == -1{
group.kill().expect("[Error] killing api server process.");
}
}
});
}
fn main() {
let (tx, rx) = sync_channel(1);
start_backend(rx);
tauri::Builder::default()
.on_window_event(move |event| match event.event(){
WindowEvent::Destroyed => {
tx.send(-1).expect("[Error] sending messsage.");
println!("[Event] App closed, shutting down API...");
}
_ => {}
})
.run(tauri::generate_context!())
.expect("error while running tauri application");
}
In fact, this is just about all the Rust I needed to write. The default app behavior is enough; heavy lifting is done by the Python backend and the NextJS frontend of Tauri makes it simple to implement a basic UI.
Building the backend
Now that we have an idea of what we'd need to build the application, it was time to design the sidecar.
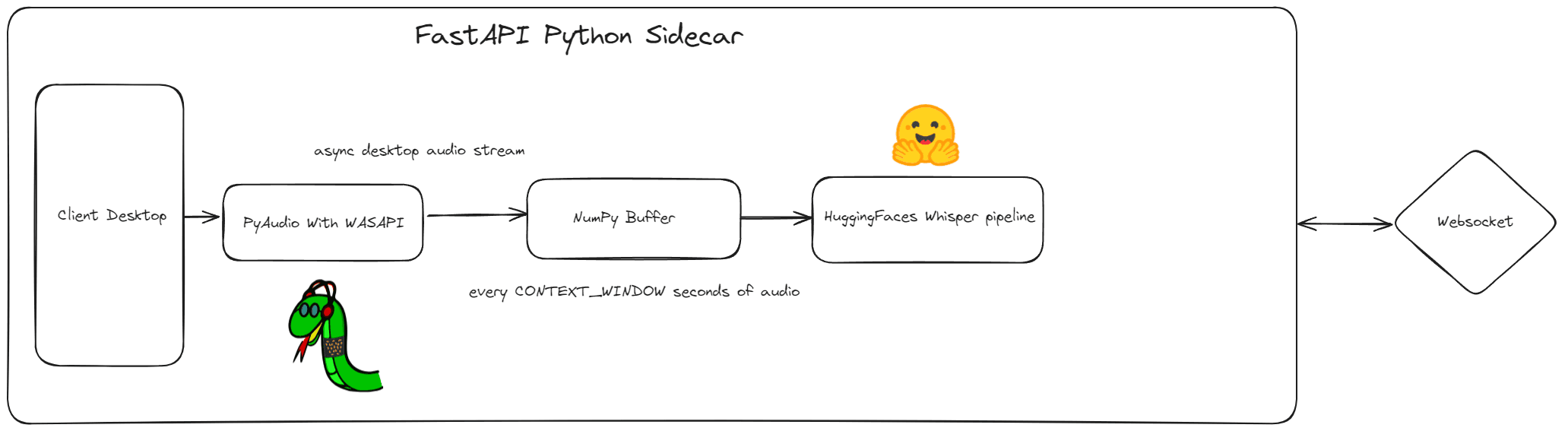
Our FastAPI server exists to facilitate one major functionality: a websocket endpoint that provisions the transcription to the JS frontend in the Tauri application. The inner workings of the endpoint are more complex, but the basic flow of the business logic is straightforward:
- Initialize an asynchronous audio stream that will constantly record the user's default speakers, found dynamically.
- This audio is fed into a NumPy buffer that is sectioned based on a defined
CONTEXT WINDOW. Every X seconds is fit to the model and translated/transcribed with some specified overlap. - The returned transcription by Whisper is sent through the websocket to be displayed in a TextArea.
Challenges with the backend
There were a few considerable challenges when designing the backend.
How should we handle the data and how much of it?
Using a buffer and an overlap makes the transcription appear with some redundancy, but a context window is important with respect to the encoder-decoder transformer. The quality of transcription is heavily dependent on how much context we have available:
- A large context window greatly increases the quality of transcription, but will reduce the availability of the software and fail to meet our latency requirements
- A small context window will not yield choppy, disjointed transcriptions. But it will be much faster and much closer to real-time.
PyTorch and the main thread
In order to avoid issues with the asynchronous audio stream and handling the ASR pipeline, a combination of Python's synchronized Queue, asyncio, and threading was used.
Building the frontend
Given that the majority of this application is facilitated by the sidecar, the remainder of the implementation is to access the websocket endpoint in TypeScript and display the transcriptions accordingly.
Fortunately, maintaining the Websocket connection with a useRef is simple enough:
const Home = () => {
const [isConnected, setIsConnected] = useState(false);
const [messages, setMessages] = useState<string[]>([]);
const [isTranslating, setIsTranslating] = useState(false);
const socketRef = useRef<WebSocket | null>(null);
useEffect(() => {
const connectWebSocket = () => {
socketRef.current = new WebSocket("ws://localhost:8008/ws");
socketRef.current.onopen = () => {
console.log("WebSocket is open now.");
setIsConnected(true);
};
socketRef.current.onmessage = (event) => {
console.log("Received from server: " + event.data);
setMessages((prev) => [...prev, event.data]);
};
socketRef.current.onerror = (event) => {
console.error("WebSocket error observed:", event);
};
socketRef.current.onclose = () => {
console.log("WebSocket is closed now.");
setIsConnected(false);
};
};
connectWebSocket();
return () => {
if (socketRef.current) {
socketRef.current.close();
}
};
}, []);
const startRecording = () => {
setIsTranslating(true);
if (socketRef.current && socketRef.current.readyState === WebSocket.OPEN) {
const message = JSON.stringify({ command: "start" });
socketRef.current.send(message);
}
};
const stopRecording = () => {
if (socketRef.current && socketRef.current.readyState === WebSocket.OPEN) {
const message = JSON.stringify({ command: "stop" });
socketRef.current.send(message);
}
setIsTranslating(false);
};
}
We then load the messages as they appear in a textarea. And that is pretty much it! Throw a YouTube video in Spanish, or perhaps you simply want to have English subtitles--all you need to do is open the Tauri exe and hit the start button.
So how did we do?
There are still quite a few pain points with the current application, and if/when they are eliminated this article will be amended as such:
- The UI could be much prettier, and add some accessibility and comfort features. Perhaps allowing the user to select the context window, or loading screens.
- Speaking of loading, there's a bit of a delay when we first begin translation; it takes a bit for the model to begin transcribing audio data and there is no visible indication for the user.
- The transcription is only as good as Whisper is, and not just Whisper but Whisper-tiny, which I selected for it's size.
- Whisper works well for popular languages like English and Spanish, and significantly degrades in performance as the incoming language is less and less common.
Yet the application does succeed in it's major purpose:
The user can effectively transcribe and translate audio that comes through the desktop in real-time. Playing back an English video boasts very high accuracy, Japanese..not so much. This limitation is also a limitation implicit to the ASR model and multilingual training sets--if we want better performance on one language, fine-tuning becomes an important future task. But then, we can't fine-tune for every situation--if we did, we may as well make a Taurscribe : K-Drama edition, or Taurscribe : Anime edition--an approach that contradicts our initial motivation of having a one stop shop for audio transcription.
I do think these are interesting ideas, and for power users or consumers who partake in a specific medium more than anything else, we can drill down the use case to provide a catered and custom experience.
But as it is now, Taurscribe does do what we wanted it to do: pick any audio source--music, online video, a downloaded movie, even your friend on a VOIP app--Taurscribe will translate and transcribe it.
Although it might not be a great translation.
← Previous